Information Technology teams, especially in help desk and support, need a way to track what problems people are having. Ideally they also can know how those problems change over time, especially when technology or policy shifts.
Imagine you are in charge of sending a newspaper delivery team to different neighborhoods. Each person has a bicycle, so you give them a route, and they leave the papers at the right doors. But the roads change. Every day they change. It’s chaos.
From our partners:
What do you do when routes are changing constantly? How do you provide the information needed when the context is shifting all the time?
In an IT context we run into similar challenges with traditional problem management frameworks such as ITIL 4, which tend to always assume a fixed, well-defined catalog of services. That way every issue that the IT folks solve is tracked and accounted for. That connection back to the catalog allows insight into what’s causing issues, or where outages or incidents may be impacting a large group of employees.
At Google we don’t have that. In part because we focus on putting the user first, and so we focus on getting people back to a productive state as job #1. Also because products, services and issues are always shifting–just like the roads, the route is never the same, even if the goal remains consistent. That means users come into our IT service desk with new problem types everyday.
Our tech support team, called Techstop, acts as the one-stop shop for all IT issues, and supports people across chat, email and video channels. They need to remain adaptable to new problems Googlers experience and new products they use. In order to track what problems might be on the rise, the Techstop team needs a way to catalog what tools, applications and services are in use at Google.
Thinking back to the newspaper delivery routes, we used a rough approximate map, rather than a very detailed one, giving us a taxonomy of services that was “good enough” for most of our use cases. We got some useful data out of it, but it didn’t give us very granular insight.
Need for innovation
Covid-19 put a new focus on scalable problem understanding, specifically for everyday employee IT issues. With so much of the workforce moved to a work-from-home model, we really needed to know where employees were experiencing technology pain. It’s as if whole new neighborhoods popped into existence overnight, but our newspaper delivery crew was the same. More ground to cover, with totally novel street maps.
Furthermore, products used everyday for productivity, such as Google Meet, began to see exponential growth in usage, causing scaling issues and outages. These product teams looked to the Techstop organization to help them prioritize the ever increasing list of feature requests and bugs being filled every day.
Ultimately the “good enough” problem taxonomy failed to produce truly helpful insights. We could find out which products were being affected the most, but not what issues people were having with those products. Even worse, new issues that were unique to the work-from-home model were being hidden by the fact that the catalog could not update in time to catch the rapidly changing problem space underneath it.
Borrowing spam tech
Taking a look around other efforts at Google, the Techstop team found examples of solving a similar problem: detecting new patterns quickly in rapidly changing data.
Gmail handles spam filtering for over a billion people. Those engineers had thought through “how do we detect a new spam campaign quickly?” Spammers rapidly send bulk messages with slight variations in content (noise, misspellings, etc.) Most classification attempts would become a game of cat and mouse since it takes classifiers some time to learn about new patterns.

Invoking a trend identification engine using unsupervised density clustering on unstructured text unlocked the ability for Gmail to detect ephemeral spam campaigns more quickly.
The Techstop problem had a similar shape to it. Issues caused by rapidly changing products caused highly dynamic user journeys for both employees and the IT professionals troubleshooting these issues. The tickets filed — like the spam emails — were similar, with slight differences in spelling and word choice.
Density clustering
In contrast to more rigid approaches, such as centroid-based algorithms like k-means, density-based clustering is better suited to large and highly heterogeneous data sets, which may contain clusters of drastically variant size. This flexibility helps us tackle the task of problem identification across the entire scope of the company, which requires the ability to detect and distinguish small-but-significant perturbations in the presence of large-but-stable patterns.
Our implementation uses ClustOn, an in-house technology with a hybrid approach that incorporates density-based clustering. But a more time-tested algorithm such as DBSCAN — an open-source implementation of which is available via scikit-learn’s clustering module — could be leveraged to similar effect.
Middle of the road solution using ML
Piggy-backing off of what Gmail was able to do using density clustering techniques, the Techstop team built a robust solution to tracking problems in a way that solved the rigid taxonomy problem. With density clustering, the taxonomy buckets are redefined as trending clusters and provide an index of issues happening in real-time within the company. Importantly, these buckets emerge naturally, rather than being defined ahead of time by the Engineering or Tech Support teams.
By using the technology built for billions of email accounts, we knew we could handle the scale of Google’s support requests. And the solutions would be more flexible than a tightly defined taxonomy, without compromising on relevance or granularity.
The team took it one step further by modeling cluster behavior using Poisson regression and implemented anomaly detection measures to alert operations teams in real time about ongoing outages, or poorly executed changes. With a lightweight operations team and this new technology, Techstop was able to find granular insights that would have taken an entire dedicated team to manually comb through and aggregate each incident.
The combination of ML and Operations transformed Techstop data into a valuable reference for product managers and engineering teams looking to understand the issues users face with their products in an enterprise environment.
How it works
To bring it all together, we built a ML pipeline that we call Support Insights, so we could automatically distill summary data from the many interactions and tickets we received. The Support Insights Pipeline combines machine learning, human validation and probabilistic analysis together in a single systems dynamics approach.
As data moves through this pipeline, they are:
- Extracted – Uses the BigQuery API to store and extract, train and load support data. To ingest the 1M+ amount of IT related support data.
- Processed Part-of-speech tagging, PII Redaction and TF-IDF transformations to model support data for our clustering algorithms
- Clustered Centroid-based clustering runs in timed batches with persistent snaphotting of previous run states to maintain cluster ids and track behavior of clusters over time.
- Scored Uses Poisson Regression to model both long-term and short-term behavior of cluster trends and calculates the difference between the two to measure deviation. This deviation score is used to detect anomalous behavior within a trend.
- Operationalized Trends with an anomalous score over a certain threshold trigger an IssueTracker API bug. This bug is then picked up by operations teams for relevant deep dive and incident tracking.
- Resampled – Uses statistical methods to estimate proportions of customer user journeys (CUJs) within trends
- Categorized/mapped – We work with the Operations teams to map trend proportions to User Journey Segments
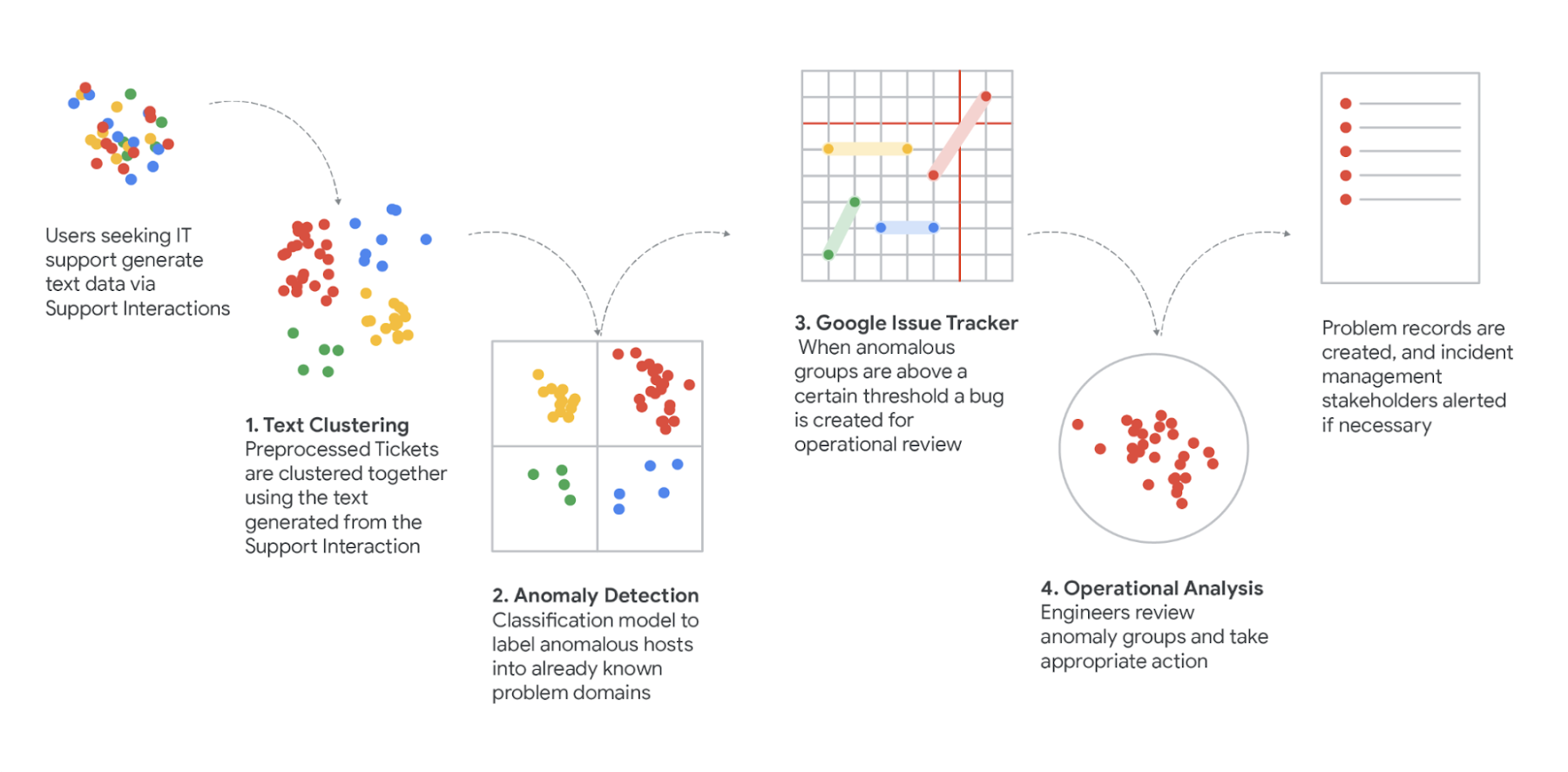
In our next post we’ll detail what technologies and methods we used for these seven steps, and walk through how you could use a similar pipeline yourself. To get started start by loading your data into BigQuery and use BigQuery ML to cluster your support data.
By Nicholaus Jackson, Efficiency Solutions Engineer | Max Saltonstall Senior Developer Relations Engineer, Google Cloud
Source Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!