
Build a secure and governed Iceberg data lake with BigLake’s fine-grained security model
BigLake enables multi-compute architecture: Iceberg tables created in supported open source analytics engines can be read using BigQuery.
From our partners:
# Creation of table using Iceberg format with Dataproc Spark
CREATE TABLE catalog.db.table (col1 type1, col2 type2) USING iceberg TBLPROPERTIES(bq_table='{bigquery_table}', bq_connection='{bigquery_connection}');
# Query table using the BigQuery console
SELECT COL1, COL2 FROM bigquery_table LIMIT 10;
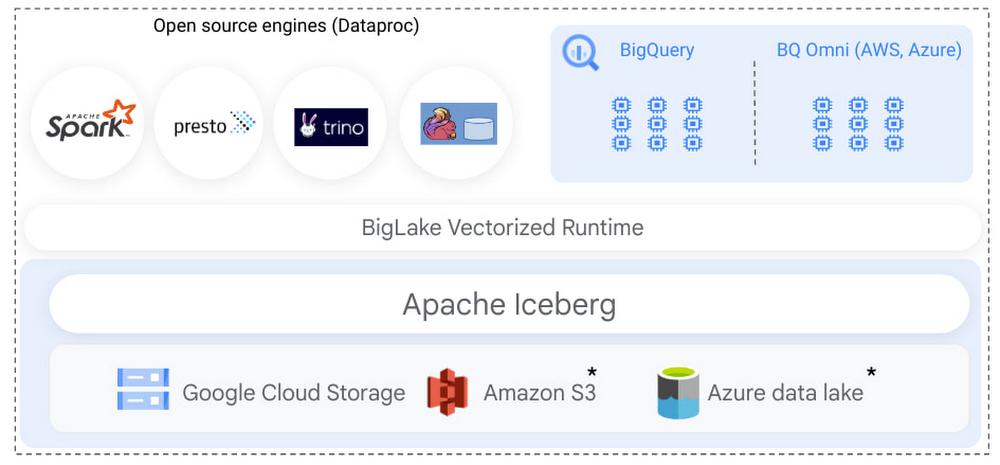
Differentiate your Iceberg workloads with native BigQuery and GCP integration
The benefits of running Iceberg on Google Cloud extend beyond realizing Iceberg’s core capabilities and BigLake’s fine-grained security model. Customers can use native BigQuery and GCP integration to use BigQuery’s differentiated services on Iceberg tables created over Google Cloud Storage data. Some key integrations most relevant in the context of Iceberg are:
- Securely exchange Iceberg data using Analytics Hub – Iceberg as an open standard provides interoperability between various storage systems and query engines to exchange data. On Google Cloud, customers use Analytics hub to share BigQuery & BigLake tables with their partners, customers, and suppliers without needing to copy data. Similar to BigQuery tables, data providers can now create shared datasets to share Iceberg tables on Google Cloud storage. Consumers of the shared data can use any Iceberg compatible supported query engine to consume the data, providing an open and governed model of sharing and consuming data.
- Run data science workloads on Iceberg using BigQueryML – Customers can now use BigQueryML to extend their machine learning workloads to Iceberg tables stored on Google cloud storage, enabling customers to realize AI value on data stored outside of BigQuery.
- Discover, detect and protect PII data on Iceberg using Cloud DLP – Customers can now use Cloud DLP to identify, discover and secure PII data elements contained in Iceberg tables, and secure sensitive data using BigLake’s fine-grained security model to meet workload compliance.
Get Started
Learn more about BigLake support for Apache Iceberg by watching this demo video, and a panel discussion of customers building using BigLake with Iceberg. Apache Iceberg support for BigLake is currently in preview, sign up to get started. Contact a Google sales representative to learn how Apache Iceberg can help evolve your data architecture.
Special mention to the engineering leadership of Micah Kornfield, Anoop Johnson, Garrett Casto, Justin Levandoski and team to make this launch possible.
By: Gaurav Saxena (Sr. Product Manager, Google Cloud) and Yuri Volobuev (Principal Engineer, Google Cloud)
Source: Google Cloud Blog
For enquiries, product placements, sponsorships, and collaborations, connect with us at [email protected]. We'd love to hear from you!
Our humans need coffee too! Your support is highly appreciated, thank you!







